Superdesign


AI-powered design platform for creating beautiful interfaces and experiences
Fabric - open-source framework of crowdsourced AI prompts

Fabric is an open-source framework for augmenting humans using AI. It provides a modular system for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere. - danielmiessler/Fabric
https://www.opensourceprojects.dev/post/e548ac30-a0c6-4396-b81e-892568966088
The Prompt Engineering Playbook for Programmers

AI pair programmers are powerful but not magical – they have no prior knowledge of your specific project or intent beyond what you tell them or include as context. The more information you provide, the better the output. We’ll distill key prompt patterns, repeatable frameworks, and memorable examples that have resonated with developers. You’ll see side-by-side comparisons of good vs. bad prompts with actual AI responses, along with commentary to understand why one succeeds where the other falters. Here’s a cheat sheet to get started:
The Great Perl Toolchain Summit CLI Throwdown 2026 · olafalders.com

A roundup of the command-line tools and terminal setups shared at the 2026 edition of our now-annual CLI throwdown at the Perl Toolchain Summit.
- eza
- superpowers
- fastgron
- fx
- dyff
The <(...) syntax runs a command and presents its output as if it were a file (pipe), which lets you feed command output to programs that expect a filename.
# See how the contents of two directories differ
diff <(ls dir-one) <(ls dir-two)https://www.olafalders.com/2025/06/03/the-great-pts-cli-throwdown/
- yazi
- tailscale
- neovim plugins
- bat
- typos
- shutter (linux)
Other tools
- ncdu - ncdu (NCurses Disk Usage) is an interactive, text-based disk space analyzer.
Superpowers: How I'm using coding agents in October 2025 — Massively Parallel Procrastination

I'm Jesse. I make stuff. Software, hardware. Very occasionally, trouble.
GitHub - addyosmani/gemini-cli-tips: Gemini CLI Tips and Tricks · GitHub
Gemini CLI Tips and Tricks. Contribute to addyosmani/gemini-cli-tips development by creating an account on GitHub.
STOP TELLING CHATGPT TO "WRITE AN E-MAIL FOR ME". | The AI Colony @TheAIColony
1. The Professional Email Writer
“Act as a senior communication specialist. Rewrite this email to sound professional, clear, concise, and polite while keeping my original intent. Improve tone, structure, grammar, and flow. My email: [paste email].”
3. The Corporate Reply
“Craft a professional reply to this email I received: [paste email]. Maintain a respectful tone, address all points clearly, and write a response that strengthens trust and communication.”
Other prompts:
https://www.theailibrary.co/prompts
The complete claude code tutorial | @eyad_khrais
Think First
Most people assume that with Claude Code and other AI tools, the first thing you need to do is type (or start talking). But that's probably one of the biggest mistakes that you can make straight off the bat. The first thing that you actually need to do is think.
Have a deep back and forth with ChatGPT/Gemini/Claude, where you describe exactly what you want to build, you ask the LLM for the various options you can take in terms of system design, and ultimately the two of you settle on a solution. You and the LLM should be asking each other questions, not just a one way street.
Before you ask Claude to build a feature, think about the architecture. Before you ask it to refactor something, think about what the end state should look like. Before you ask it to debug, think about what you actually know about the problem. The more information that you have in plan mode, the better your output is actually going to be because the better the input is going to be.
Keep it short.
Claude can only reliably follow around 150 to 200 instructions at a time, and Claude Code's system prompt already uses about 50 of those.
Tell it why, not just what. Claude is a little bit like a human in this way. When you give it the reason behind an instruction, Claude implements it better than if you just tell it what to do.
Update it constantly.
Press the # key while you're working and Claude will add instructions to your CLAUDE.md automatically.
Use external memory.
If you're working on something complex, have Claude write plans and progress to actual files (I use SCRATCHPAD.md or plan.md). These persist across sessions. When you come back tomorrow, Claude can read the file and pick up where you left off instead of starting from zero.
When Claude Gets Stuck
Simplify the task
Agents | Chip Huyen
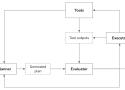
-
An overview of agents
-
How the capability of an AI-powered agent is determined by the set of tools it has access to and its capability for planning
-
How to select the best set of tools for your agent
-
Whether LLMs can plan and how to augment a model’s capability for planning
-
Agent’s failure modes
AI-powered agents are an emerging field with no established theoretical frameworks for defining, developing, and evaluating them. This post is a best-effort attempt to build a framework from the existing literature, but it will evolve as the field does.
Karpathy's 4 CLAUDE.md rules cut Claude mistakes from 41% to 11%. After 30 codebases, I added 8 more
Lots of good replies, some that say he is FOS. Others point out that these might be too restrictive for everyday tasks.
I quite like the new DeepSeek-OCR paper | Andrej Karpathy
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in.
I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
Designing agentic loops
My preferred definition of an LLM agent is something that runs tools in a loop to achieve a goal. The art of using them well is to carefully design the tools and loop for them to use.
- The joy of YOLO mode
- Picking the right tools for the loop
- Issuing tightly scoped credentials
- When to design an agentic loop
- This is still a very fresh area
AddyOsmani.com - Agent Skills

AI coding agents take the shortest path to done, which usually means skipping the specs, tests, and reviews that make software reliable at scale. Agent Skill...
https://x.com/datachaz/status/2040357775830814798?s=43&t=gAZhA3-2h2DvLb-eSzGa5A
https://github.com/addyosmani/agent-skills
@addyosmani
from Google just dropped his new Agent Skills and it's incredible.
It brings 19 engineering skills + 7 commands to AI coding agents, all inspired by Google best practices 🤯
AI coding agents are powerful, but left alone, they take shortcuts.
They skip specs, tests, and security reviews, optimizing for "done" over "correct." Addy built this to fix that.
Each skill encodes the workflows and quality gates that senior engineers actually use: spec before code, test before merge, measure before optimize.
The full lifecycle is covered:
→ Define - refine ideas, write specs before a single line of code
→ Plan - decompose into small, verifiable tasks
→ Build - incremental implementation, context engineering, clean API design
→ Verify - TDD, browser testing with DevTools, systematic debugging
→ Review - code quality, security hardening, performance optimization
→ Ship - git workflow, CI/CD, ADRs, pre-launch checklists
Features 7 slash commands: (/spec, /plan, /build, /test, /review, /code-simplify, /ship) that map to this lifecycle.
Should LLMs just treat text content as an image?

https://news.ycombinator.com/item?id=45652952
According to the DeepSeek paper, you can pull out 10 text tokens from a single image token with near-100% accuracy. In other words, a model’s internal representation of an image is ten times as efficient as its internal representation of text. Does this mean that models shouldn’t consume text at all? When I paste a few paragraphs into ChatGPT, would it be more efficient to convert that into an image of text before sending it to the model? Can we supply 10x or 20x more data to a model at inference time by supplying it as an image of text instead of text itself?
Dicklesworthstone (Jeff Emanuel) · GitHub

Building in NY. Dicklesworthstone has 179 repositories available. Follow their code on GitHub.
Fine-Tuning LLMs is a Huge Waste of Time - by Devansh

People think they can use Fine-Tune for Knowledge Injection. People are Wrong
https://news.ycombinator.com/item?id=44242737
If fine-tuning is a risky solution, what’s the alternative? The answer lies in modularity and augmentation. Techniques such as retrieval-augmented generation (RAG), external memory banks, and adapter modules provide more robust ways to incorporate new information without overwriting the existing network’s knowledge base.
GitHub - addyosmani/bg-remove: Free image background removal

Free image background removal - private, client-side and powered by Transformers.js - addyosmani/bg-remove
Gemini 3.1 Pro in Gemini CLI still holds its own.
Googles system prompt of the CLI is heavily flawed IMO. That's where most problems arise. I am using a custom one. At least it is highly configurable. The vanilla Gemini Cli is not usable for me. For instance, they have a section they introduce with Proactiveness where they give advice about what is Persistence (in the agent loop). This wrong wording alone causes the agent to be "proactive" in many ways that is not wanted. After I asked the model itself once, why it started to scan my entire codebase when I just asked to create a new branch, it directly said to me there is "Proactiveness" in its system prompt. I was baffled, why would anybody want that? So i digged deeper and did also a thorough analysis with Opus 4.7 of just this system prompt file - that cost me an entire Pro-session btw. - and documented the results in this pr: https://github.com/google-gemini/gemini-cli/pull/26129 - I am using the optimized prompt and had no issues so far I had with the original one.
Another big issue is "model panic" - the Gemini model often overwrites entire files "from memory" with write_file, when the edit tool fails 2 times. That occasionally causes code degradation, and when there are multiple turns and there is no backup, the model starts to get nuts, trying to fix its errors, and destroys even more in the effort to just make it compile / build. I gave it a rotating pre-write backup and a restore_file tool. The model panic vanished. https://github.com/google-gemini/gemini-cli/pull/25947
With these two fixes, Gemini CLI is pretty good - without them I wouldn't use it.
How many AIs does it take to read a PDF? | Verge

For all of the AI industry’s advancements, the major models like ChatGPT and Claude still struggle with PDFs, one of the oldest and ubiquitous file formats.
How to Build an Agent

Building a fully functional, code-editing agent in less than 400 lines.